表 & 视图¶
All views and tables in the active schema and accessible by the active database role for a request are available for querying. They are exposed in one-level deep routes. For instance the full contents of a table people is returned at
GET /people HTTP/1.1
There are no deeply/nested/routes. Each route provides OPTIONS, GET, POST, PATCH, and DELETE verbs depending entirely on database permissions.
注解
Why not provide nested routes? Many APIs allow nesting to retrieve related information, such as /films/1/director. We offer a more flexible mechanism (inspired by GraphQL) to embed related information. It can handle one-to-many and many-to-many relationships. This is covered in the section about 资源嵌套.
水平过滤 (Rows)¶
You can filter result rows by adding conditions on columns, each condition a query string parameter. For instance, to return people aged under 13 years old:
GET /people?age=lt.13 HTTP/1.1
Adding multiple parameters conjoins the conditions:
GET /people?age=gte.18&student=is.true HTTP/1.1
These operators are available:
| abbreviation | meaning |
|---|---|
| eq | equals |
| gte | greater than or equal |
| gt | greater than |
| lte | less than or equal |
| lt | less than |
| neq | not equal |
| like | LIKE operator (use * in place of %) |
| ilike | ILIKE operator (use * in place of %) |
| in | one of a list of values e.g. ?a=in.1,2,3 – also supports commas in quoted strings like ?a=in."hi,there","yes,you" |
| is | checking for exact equality (null,true,false) |
| @@ | full-text search using to_tsquery |
| @> | contains e.g. ?tags=@>.{example, new} |
| <@ | contained in e.g. ?values=<@{1,2,3} |
| not | negates another operator, see below |
To negate any operator, prefix it with not like ?a=not.eq.2.
For more complicated filters (such as those involving disjunctions) you will have to create a new view in the database, or use a stored procedure. For instance, here's a view to show "today's stories" including possibly older pinned stories:
CREATE VIEW fresh_stories AS
SELECT *
FROM stories
WHERE pinned = true
OR published > now() - interval '1 day'
ORDER BY pinned DESC, published DESC;
The view will provide a new endpoint:
GET /fresh_stories HTTP/1.1
注解
We're working to extend the PostgREST query grammar to allow more complicated boolean logic, while continuing to prevent performance problems from arbitrary client queries.
垂直过滤 (Columns)¶
When certain columns are wide (such as those holding binary data), it is more efficient for the server to withold them in a response. The client can specify which columns are required using the select parameter.
GET /people?select=fname,age HTTP/1.1
The default is *, meaning all columns. This value will become more important below in 资源嵌套.
计算列¶
Filters may be applied to computed columns as well as actual table/view columns, even though the computed columns will not appear in the output. For example, to search first and last names at once we can create a computed column that will not appear in the output but can be used in a filter:
CREATE TABLE people (
fname text,
lname text
);
CREATE FUNCTION full_name(people) RETURNS text AS $$
SELECT $1.fname || ' ' || $1.lname;
$$ LANGUAGE SQL;
-- (optional) add an index to speed up anticipated query
CREATE INDEX people_full_name_idx ON people
USING GIN (to_tsvector('english', full_name(people)));
A full-text search on the computed column:
GET /people?full_name=@@.Beckett HTTP/1.1
As mentioned, computed columns do not appear in the output by default. However you can include them by listing them in the vertical filtering select param:
GET /people?select=*,full_name HTTP/1.1
排序¶
The reserved word order reorders the response rows. It uses a comma-separated list of columns and directions:
GET /people?order=age.desc,height.asc HTTP/1.1
If no direction is specified it defaults to ascending order:
GET /people?order=age HTTP/1.1
If you care where nulls are sorted, add nullsfirst or nullslast:
GET /people?order=age.nullsfirst HTTP/1.1
GET /people?order=age.desc.nullslast HTTP/1.1
You can also use 计算列 to order the results, even though the computed columns will not appear in the output.
Limit 和分页¶
PostgREST uses HTTP range headers to describe the size of results. Every response contains the current range and, if requested, the total number of results:
HTTP/1.1 200 OK
Range-Unit: items
Content-Range: 0-14/*
Here items zero through fourteen are returned. This information is available in every response and can help you render pagination controls on the client. This is an RFC7233-compliant solution that keeps the response JSON cleaner.
There are two ways to apply a limit and offset rows: through request headers or query params. When using headers you specify the range of rows desired. This request gets the first twenty people.
GET /people HTTP/1.1
Range-Unit: items
Range: 0-19
Note that the server may respond with fewer if unable to meet your request:
HTTP/1.1 200 OK
Range-Unit: items
Content-Range: 0-17/*
You may also request open-ended ranges for an offset with no limit, e.g. Range: 10-.
The other way to request a limit or offset is with query parameters. For example
GET /people?limit=15&offset=30 HTTP/1.1
This method is also useful for embedded resources, which we will cover in another section. The server always responds with range headers even if you use query parameters to limit the query.
In order to obtain the total size of the table or view (such as when rendering the last page link in a pagination control), specify your preference in a request header:
GET /bigtable HTTP/1.1
Range-Unit: items
Range: 0-24
Prefer: count=exact
Note that the larger the table the slower this query runs in the database. The server will respond with the selected range and total
HTTP/1.1 206 Partial Content
Range-Unit: items
Content-Range: 0-24/3573458
相应格式¶
PostgREST uses proper HTTP content negotiation (RFC7231) to deliver the desired representation of a resource. That is to say the same API endpoint can respond in different formats like JSON or CSV depending on the client request.
Use the Accept request header to specify the acceptable format (or formats) for the response:
GET /people HTTP/1.1
Accept: application/json
The current possibilities are
- */*
- text/csv
- application/json
- application/openapi+json
- application/octet-stream
The server will default to JSON for API endpoints and OpenAPI on the root.
单数或复数¶
By default PostgREST returns all JSON results in an array, even when there is only one item. For example, requesting /items?id=eq.1 returns
[
{ "id": 1 }
]
This can be inconvenient for client code. To return the first result as an object unenclosed by an array, specify vnd.pgrst.object as part of the Accept header
GET /items?id=eq.1 HTTP/1.1
Accept: application/vnd.pgrst.object+json
This returns
{ "id": 1 }
When a singular response is requested but no entries are found, the server responds with an empty body and 404 status code rather than the usual empty array and 200 status.
注解
Many APIs distinguish plural and singular resources using a special nested URL convention e.g. /stories vs /stories/1. Why do we use /stories?id=eq.1? The answer is because a singlular resource is (for us) a row determined by a primary key, and primary keys can be compound (meaning defined across more than one column). The more familiar nested urls consider only a degenerate case of simple and overwhelmingly numeric primary keys. These so-called artificial keys are often introduced automatically by Object Relational Mapping libraries.
Admittedly PostgREST could detect when there is an equality condition holding on all columns constituting the primary key and automatically convert to singular. However this could lead to a surprising change of format that breaks unwary client code just by filtering on an extra column. Instead we allow manually specifying singular vs plural to decouple that choice from the URL format.
二进制输出¶
If you want to return raw binary data from a bytea column, you must specify application/octet-stream as part of the Accept header
and select a single column ?select=bin_data.
GET /items?select=bin_data&id=eq.1 HTTP/1.1
Accept: application/octet-stream
注解
If more than one row would be returned the binary results will be concatenated with no delimiter.
资源嵌套¶
In addition to providing RESTful routes for each table and view, PostgREST allows related resources to be included together in a single API call. This reduces the need for multiple API requests. The server uses foreign keys to determine which tables and views can be returned together. For example, consider a database of films and their awards:
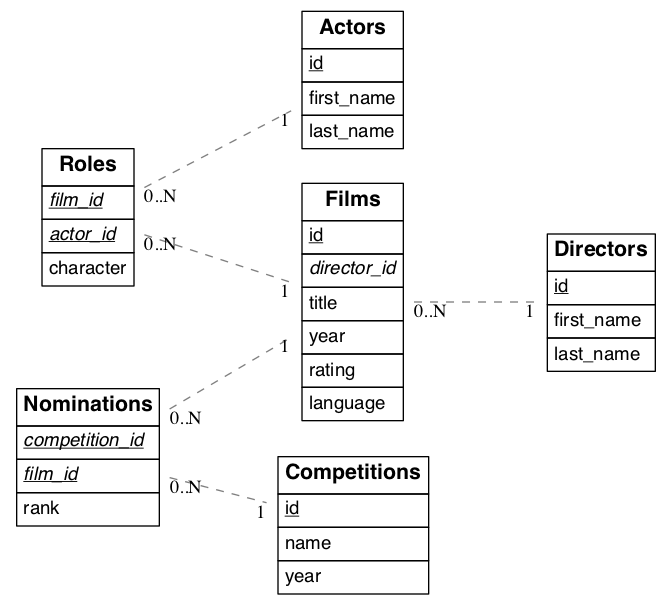
As seen above in 垂直过滤 (Columns) we can request the titles of all films like this:
GET /films?select=title HTTP/1.1
This might return something like
[
{ "title": "Workers Leaving The Lumière Factory In Lyon" },
{ "title": "The Dickson Experimental Sound Film" },
{ "title": "The Haunted Castle" }
]
However because a foreign key constraint exists between Films and Directors, we can request this information be included:
GET /films?select=title,directors(last_name) HTTP/1.1
Which would return
[
{ "title": "Workers Leaving The Lumière Factory In Lyon",
"directors": {
"last_name": "Lumière"
}
},
{ "title": "The Dickson Experimental Sound Film",
"directors": {
"last_name": "Dickson"
}
},
{ "title": "The Haunted Castle",
"directors": {
"last_name": "Méliès"
}
}
]
注解
As of PostgREST v4.1, parens () are used rather than brackets {} for the list of embedded columns. Brackets are still supported, but are deprecated and will be removed in v5.
PostgREST can also detect relations going through join tables. Thus you can request the Actors for Films (which in this case finds the information through Roles). You can also reverse the direction of inclusion, asking for all Directors with each including the list of their Films:
GET /directors?select=films(title,year) HTTP/1.1
注解
Whenever foreign key relations change in the database schema you must refresh PostgREST's schema cache to allow resource embedding to work properly. See the section Schema 重载.
嵌入过滤和排序¶
Embedded tables can be filtered and ordered similarly to their top-level counterparts. To do so, prefix the query parameters with the name of the embedded table. For instance, to order the actors in each film:
GET /films?select=*,actors(*)&actors.order=last_name,first_name HTTP/1.1
This sorts the list of actors in each film but does not change the order of the films themselves. To filter the roles returned with each film:
GET /films?select=*,roles(*)&roles.character=in.Chico,Harpo,Groucho HTTP/1.1
Once again, this restricts the roles included to certain characters but does not filter the films in any way. Films without any of those characters would be included along with empty character lists.
自定义查询¶
The PostgREST URL grammar limits the kinds of queries clients can perform. It prevents arbitrary, potentially poorly constructed and slow client queries. It's good for quality of service, but means database administrators must create custom views and stored procedures to provide richer endpoints. The most common causes for custom endpoints are
- Table unions and OR-conditions in the where clause
- More complicated joins than those provided by 资源嵌套
- Geospatial queries that require an argument, like "points near (lat,lon)"
- More sophisticated full-text search than a simple use of the
@@filter
存储过程¶
Every stored procedure in the API-exposed database schema is accessible under the /rpc prefix. The API endpoint supports only POST which executes the function.
POST /rpc/function_name HTTP/1.1
Such functions can perform any operations allowed by PostgreSQL (read data, modify data, and even DDL operations). However procedures in PostgreSQL marked with stable or immutable volatility can only read, not modify, the database and PostgREST executes them in a read-only transaction compatible for read-replicas.
Procedures must be used with named arguments. To supply arguments in an API call, include a JSON object in the request payload and each key/value of the object will become an argument.
For instance, assume we have created this function in the database.
CREATE FUNCTION add_them(a integer, b integer)
RETURNS integer AS $$
SELECT $1 + $2;
$$ LANGUAGE SQL IMMUTABLE STRICT;
The client can call it by posting an object like
POST /rpc/add_them HTTP/1.1
{ "a": 1, "b": 2 }
The keys of the object match the parameter names. Note that PostgreSQL converts parameter names to lowercase unless you quote them like CREATE FUNCTION foo("mixedCase" text) .... You can also call a function that takes a single parameter of type json by sending the header Prefer: params=single-object with your request. That way the JSON request body will be used as the single argument.
注解
We recommend using function arguments of type json to accept arrays from the client. To pass a PostgreSQL native array you'll need to quote it as a string:
POST /rpc/native_array_func HTTP/1.1
{ "arg": "{1,2,3}" }
POST /rpc/json_array_func HTTP/1.1
{ "arg": [1,2,3] }
PostgreSQL has four procedural languages that are part of the core distribution: PL/pgSQL, PL/Tcl, PL/Perl, and PL/Python. There are many other procedural languages distributed as additional extensions. Also, plain SQL can be used to write functions (as shown in the example above).
By default, a function is executed with the privileges of the user who calls it. This means that the user has to have all permissions to do the operations the procedure performs. Another option is to define the function with with the SECURITY DEFINER option. Then only one permission check will take place, the permission to call the function, and the operations in the function will have the authority of the user who owns the function itself. See PostgreSQL documentation for more details.
注解
Why the /rpc prefix? One reason is to avoid name collisions between views and procedures. It also helps emphasize to API consumers that these functions are not normal restful things. The functions can have arbitrary and surprising behavior, not the standard "post creates a resource" thing that users expect from the other routes.
We are considering allowing GET requests for functions that are marked non-volatile. Allowing GET is important for HTTP caching. However we still must decide how to pass function parameters since request bodies are not allowed. Also some query string arguments are already reserved for shaping/filtering the output.
获取请求的 Headers/Cookies¶
Stored procedures can access request headers and cookies by reading GUC variables set by PostgREST per request. They are named request.header.XYZ and request.cookie.XYZ. For example, to read the value of the Origin request header:
SELECT current_setting('request.header.origin', true);
复杂布尔逻辑¶
For complex boolean logic you can use stored procedures, an example:
CREATE FUNCTION key_customers(country TEXT, company TEXT, salary FLOAT) RETURNS SETOF customers AS $$
SELECT * FROM customers WHERE (country = $1 AND company = $2) OR salary = $3;
$$ LANGUAGE SQL;
Then you can query by doing:
POST /rpc/key_customers HTTP/1.1
{ "country": "Germany", "company": "Volkswagen", salary": 120000.00 }
抛出错误¶
Stored procedures can return non-200 HTTP status codes by raising SQL exceptions. For instance, here's a saucy function that always errors:
CREATE OR REPLACE FUNCTION just_fail() RETURNS void
LANGUAGE plpgsql
AS $$
BEGIN
RAISE EXCEPTION 'I refuse!'
USING DETAIL = 'Pretty simple',
HINT = 'There is nothing you can do.';
END
$$;
Calling the function returns HTTP 400 with the body
{
"message":"I refuse!",
"details":"Pretty simple",
"hint":"There is nothing you can do.",
"code":"P0001"
}
You can customize the HTTP status code by raising particular exceptions according to the PostgREST error to status code mapping. For example, RAISE insufficient_privilege will respond with HTTP 401/403 as appropriate.
插入/修改¶
All tables and auto-updatable views can be modified through the API, subject to permissions of the requester's database role.
To create a row in a database table post a JSON object whose keys are the names of the columns you would like to create. Missing properties will be set to default values when applicable.
POST /table_name HTTP/1.1
{ "col1": "value1", "col2": "value2" }
The response will include a Location header describing where to find the new object. If the table is write-only then constructing the Location header will cause a permissions error. To successfully insert an item to a write-only table you will need to suppress the Location response header by including the request header Prefer: return=minimal.
On the other end of the spectrum you can get the full created object back in the response to your request by including the header Prefer: return=representation. That way you won't have to make another HTTP call to discover properties that may have been filled in on the server side. You can also apply the standard 垂直过滤 (Columns) to these results.
注解
When inserting a row you must post a JSON object, not quoted JSON.
Yes
{ "a": 1, "b": 2 }
No
"{ \"a\": 1, \"b\": 2 }"
Some javascript libraries will post the data incorrectly if you're not careful. For best results try one of the 客户端库 built for PostgREST.
To update a row or rows in a table, use the PATCH verb. Use 水平过滤 (Rows) to specify which record(s) to update. Here is an exmaple query setting the category column to child for all people below a certain age.
PATCH /people?age=lt.13 HTTP/1.1
{ "category": "child" }
Updates also support Prefer: return=representation plus 垂直过滤 (Columns).
注解
Beware of accidentally updating every row in a table. To learn to prevent that see 阻止全表操作.
批量插入¶
Bulk insert works exactly like single row insert except that you provide either a JSON array of objects having uniform keys, or lines in CSV format. This not only minimizes the HTTP requests required but uses a single INSERT statement on the backend for efficiency. Note that using CSV requires less parsing on the server and is much faster.
To bulk insert CSV simply post to a table route with Content-Type: text/csv and include the names of the columns as the first row. For instance
POST /people HTTP/1.1
Content-Type: text/csv
name,age,height
J Doe,62,70
Jonas,10,55
An empty field (,,) is coerced to an empty string and the reserved word NULL is mapped to the SQL null value. Note that there should be no spaces between the column names and commas.
To bulk insert JSON post an array of objects having all-matching keys
POST /people HTTP/1.1
Content-Type: application/json
[
{ "name": "J Doe", "age": 62, "height": 70 },
{ "name": "Janus", "age": 10, "height": 55 }
]
删除¶
To delete rows in a table, use the DELETE verb plus 水平过滤 (Rows). For instance deleting inactive users:
DELETE /user?active=is.false HTTP/1.1
注解
Beware of accidentally deleting all rows in a table. To learn to prevent that see 阻止全表操作.
OpenAPI 支持¶
Every API hosted by PostgREST automatically serves a full OpenAPI description on the root path. This provides a list of all endpoints, along with supported HTTP verbs and example payloads.
You can use a tool like Swagger UI to create beautiful documentation from the description and to host an interactive web-based dashboard. The dashboard allows developers to make requests against a live PostgREST server, provides guidance with request headers and example request bodies.
注解
The OpenAPI information can go out of date as the schema changes under a running server. To learn how to refresh the cache see Schema 重载.
HTTP 状态码¶
PostgREST translates PostgreSQL error codes into HTTP status as follows:
| PostgreSQL error code(s) | HTTP status | Error description |
|---|---|---|
| 08* | 503 | pg connection err |
| 09* | 500 | triggered action exception |
| 0L* | 403 | invalid grantor |
| 0P* | 403 | invalid role specification |
| 23503 | 409 | foreign key violation |
| 23505 | 409 | uniqueness violation |
| 25* | 500 | invalid transaction state |
| 28* | 403 | invalid auth specification |
| 2D* | 500 | invalid transaction termination |
| 38* | 500 | external routine exception |
| 39* | 500 | external routine invocation |
| 3B* | 500 | savepoint exception |
| 40* | 500 | transaction rollback |
| 53* | 503 | insufficient resources |
| 54* | 413 | too complex |
| 55* | 500 | obj not in prereq state |
| 57* | 500 | operator intervention |
| 58* | 500 | system error |
| F0* | 500 | conf file error |
| HV* | 500 | foreign data wrapper error |
| P0001 | 400 | default code for "raise" |
| P0* | 500 | PL/pgSQL error |
| XX* | 500 | internal error |
| 42883 | 404 | undefined function |
| 42P01 | 404 | undefined table |
| 42501 | if authed 403, else 401 | insufficient privileges |
| other | 500 |